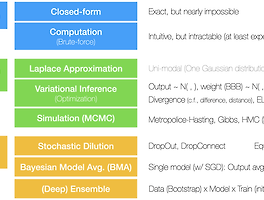
전체 글 (1181) 썸네일형 리스트형 비공식 베이지언 딥러닝 체계 **Unofficial** 이직 후로 아직 업무를 본격 시작하기 전이어서 몇 가지 공부하고 있다. 산학 과제 때문에 Bayesian Deep Learning (BDL)을 좀 공부했는데, 카카오에 있을 때부터 이걸 계속 뒤로 미룬 이유를 알 것 같다. 나는 기본적으로 Frequentist여서 Bayesian의 방식을 받아들이기가 너무 어렵다. 여러 강의 자료와 많은 논문을 읽으면서 나름 가장 기초적인 걸 깨우친 듯해서 정리하려 한다. 좀 이상한 점은 BDL이 꽤 많이 연구됐는데, 이를 다룬 Survey 논문을 찾기가 어렵다는 거다. 2~3편이 있긴 한데 분야의 폭과 깊이에 비해서 많이 부족하다. 보통 새로운 분야를 시작할 때 일단 여러 서베이 논문을 읽으면서 그 분야의 전체를 일단 조망하고 필요한 세부 기술을 익히는 방법을 주로 사.. AI 네이티브 AlphaGo Kids 2006년에 처음 '딥러닝'이란 용어가 제프리 힌튼 교수의 논문에 등장했으니 벌써 15년이 지났다. 초기에는 당연히 이미지 처리 분야에서 회자됐을 테고, 이후 차츰 과학과 기술 전문 미디어에서 다루면서 내가 이 용어를 처음 접했던 것이 2012년으로 기억한다. 10년의 시간이 흘렀다. 본격적으로 개념과 방법론을 공부하고 트렌드를 팔로잉했던 때는 다음과 카카오가 합병한 직후인 2014년도 겨울이었다. 이때라도 좀 더 테크니컬 하게 깊게 파고 들어갔더라면 조금은 다른 길을 걷고 있었을 텐데란 생각도 든다. 어쨌든 대중들이 딥러닝 또는 인공지능을 각인한 것은 알파고가 등장한 2016년도다. 겨우 5년 전인데 까마득한 과거처럼 느껴진다. 내가 경험한 위의 타임라인이 현대의 인공지능 또는 딥러닝의 확산 과정과 크.. 대체 데이터와 다크 데이터 ** 주의. 소개하는 대체 데이터와 다크 데이터를 제대로 공부해서 개념을 완벽히 이해한 상태로 글을 적는 것이 아니고, 이런 개념을 소개한 유튜브 영상과 책을 소개하기 위해서 적는다. 더 자세한 내용은 직접 찾아보고 익히길 바란다. 주식하는 분들에게 유명한 3프로TV에 11월 1일에 두 개의 영상이 올라왔다. 명지대학교 박정호 특임교수의 라이브 영상을 2 편으로 쪼갠 것인데, 대체 데이터를 이용한 투자 사례를 다룬 것이다. 부끄러운 고백인데, 데이터 과학자란 업에 오래 몸담고 있지만 대체 데이터 (alternative data)란 용어를 처음 접했다. 그동안 업무/서비스와 관련된 직접적인 데이터들이 많았기 때문에 굳이 불확실성이 높은 데이터, 즉 대체 데이터에 관한 생각을 할 필요가 없었는지도 모르지만,.. 임의성의 활용 (On Randomness) 마지막 포스팅 이후로 꽤 시간이 지났다. K에서 S로 이직하면서 스스로 입단속한 것도 있고 새로운 환경에 적응하는 시간이 필요했다. 재택을 종료하고 출퇴근 시간이 길어졌고 퇴근 후에 밀린 유튜브를 보기에도 빡빡하다. 면접관의 입장에서 인터뷰가 어때야 한다는 여러 편의 글을 적었지만, 역으로 면접자의 입장에서 놓이니 글과는 미묘한 다름이 있었다. 기회가 되면 허용된 범위 내에서 K와 S의 장단점에 관한 글도 적을 수 있길 바란다. 그동안 적고 싶었던 몇 개 주제가 있었지만 이미 기억의 저편으로 지나갔고, 지난 주말에 적으려 했던 걸 짧게 적는다. 예를 들어, 랭킹 시스템을 만든다고 했을 때 가장 최악의 알고리즘은 뭘까? 내가 생각하기에 최악은 단순히 성능 (정확도)가 낮은 알고리즘이 아니라 기준이 없는 알.. 알고리즘을 경배하라? 우리는 알고리즘의 시대를 살고 있다. '알고리즘'이란 단어가 흔해졌다. 예전에는 평생 들어보지도 못했을 사람들의 입에서 알고리즘이란 단어가 심심찮게 나온다. 제대로 이해하고 말했다고는 보지 않지만 그만큼 알고리즘이란 단어가 흔해졌고 일종의 알 수 없는 전지전능한 무엇을 총칭하는 용어가 됐다. 이글에서 알고리즘의 사전적 의미까지 뒤질 필요는 없을 거다. 그냥 일반인들이 느끼는 알고리즘의 느낌적 느낌에서 시작한 글이다. 어느 순간부터 '알고리즘'은 그저 마법의 단어가 됐다. '알고리즘이 알아서 해줘요'라고 하면 모든 상황이 종결된다. 알고리즘의 간택으로 벼락 유명인이 된 콘텐츠 제작자들의 간증을 유튜브에서 심심찮게 볼 수 있다. 그 단맛을 잊지 못해서 다시 간택을 받으려고 알고리즘 친화적인 콘텐츠를 제작해서.. 최적화 알고리즘 누군가 '인생은 속도보다 방향이 중요하다'라고 말하면 이과생이 등장해서 '속도는 벡터로 이미 방향을 포함한 값이므로 속도가 아니라 속력이다'라고 정정할 거다. 정의상 속도는 힘의 방향과 힘의 크기가 결합된 벡터, 즉 '속도 = 방향 + 속력'이다. 늦더라도 언젠가는 원하는 목표를 이루는 사람들을 보면 인생에서 방향이 중요한 듯하다가도 속력이 크면 더 빨리 성공하거나 실패하더라도 아직 젊으니 새로운 도전을 할 수 있어 속력이 더 중요한 듯하기도 하다. 사람마다 가치관과 방식이 모두 다르니 방향이니 속력이니 하는 논쟁은 각자의 사정에 맞게 잘 조절하면 된다. 어쨌든 인생에서 방향과 속력이 모두 중요하듯이 최적화도 방향과 속력이 중요하다. 머신러닝 모델을 최적화하는 방법은 "An Overview of Grad.. SOTA와 휴리스틱 매우 다양한 사람들이 데이터 과학이나 기계학습에 참여하고 있다. 그 다양성을 모두 나열할 수 없지만 아주 단순화해서 양 극단의 두 부류의 데이터 과학자가 있다. 많은 문제를 감으로 해결하려는 휴리스틱파와 무조건 최고의 알고리즘을 사용해야 한다는 소타파가 있다. 쉽게 예상하듯이 나는 휴리스틱파 쪽이다. Beyesian vs Frequentist 논쟁도 아니고, 어느 쪽이 낫다/맞다를 논하려는 건 아니다. 휴리스틱 Heuristic은 '복잡하고 불확실한 상황에서 문제를 가능한 한 빨리 해결하기 위해 쓰는 직관적 판단 또는 추론' 정도로 정의한다. 어떤 사전은 '주먹구구식 셈법'이라고 소개하기도 했지만 본 글의 취지와는 맞지 않아 보인다. 어쨌든 복잡하고 불확실한 상황에서 명확한 답을 찾기 어려울 때 상황적 .. 데이터 과학자와 머신러닝 개발자 별로 대수롭지 않은 주제지만 타임라인에 왕왕 등장해서 그냥 짧게 적는다. 평소에 나는 데이터 과학자 (Data Scientist)인지 아니면 머신러닝 개발자 (ML Enginerr)인지를 궁금해한 적이 별로 없었다. 데이터 과학자가 머신러닝 개발자인 듯하고 머신러닝 개발자가 데이터 과학자인 듯하고 그게그거라 생각했다. 데이터 과학을 오래 하다 보면 머신러닝 개발자가 돼있고 반대로 머신러닝 개발을 오래 하다 보면 자연스럽게 데이터 과학자가 돼있다고 본다. 그럼에도 굳이 구분을 해야 하는 걸까? 데이터 과학자든 머신러닝 개발자든 공통적으로 수학 지식, 프로그래밍 스킬, 그리고 도메인 이해가 필요하다. 이것에 이견을 갖는 사람은 거의 없을 거다. 기본 기술 세트가 같으니 '데이터 과학자 = 머신러닝 개발자'인.. 이전 1 2 3 4 5 6 7 8 ··· 148 다음