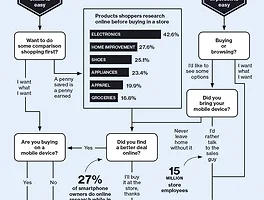
총 11번에 걸쳐서 추천 시스템과 관련된 다양한 알고리즘, measure, 고려사항 등을 다뤘습니다. 이 글에서는 미쳐 다루지 못했던 내용이나 그외 추천 시스템에 대한 잡다한 생각들을 두서없이 적으려고 합니다.
외국의 경우 아마존이나 넷플릭스, 구글유튜브 등이 추천으로 유명한 회사/서비스들이지만, 국내에는 여전히 추천 또는 데이터기반이 여전히 미약합니다. 최근에 영화 추천 서비스인 왓차, 그리고 그것을 만든 프로그래밍스가 조금 유명세를 타고 있습니다. 이전의 모든 글의 공통된 밑바탕은 추천 알고리즘 및 서비스는 별개 아니다 입니다. 현존하는 데이터마이닝 방법 중에서 추천보다 더 쉬운 것은 없다는 것이 저의 기본 가정입니다. (물론 엄청 잘하는 것은 매우 어렵습니다.)
왓차 서비스도 전혀 새로운 것이 없는데, 언론에서 과도하게 주목하는 것같다는 생각입니다. 추천 알고리즘뿐만 아니라, 왓차에서 사용하는 다양한 오픈소스들은 코딩에 조금만 재능이 있으면 누구나 사용이 가능한 아주 기본적인 것들입니다. 그럼에도 불구하고, 프로그래밍스를 높이 평가하는 것은 그런 것들을 직접 활용하고 실행에 옮겼다는 점입니다. 구슬이 서말이라도 꿰어야 보배다라는 속담처럼 주어진 재료를 이용해서 의미있는 서비스를 만들고 사용자들에게 의미를 부여해주는 바로 그 '실행'에 높은 점수를 주고 싶습니다. 국내에서도 다양한 서비스에 자동화된 추천 및 개인화 서비스가 정착했으면 좋겠습니다.
구글의 성공 이후로, 그리고 최근 빅데이터라는 버즈워드와 함께 데이터 기반 의사 결정 및 실행 Data-driven Decision making & Execution 이라는 것에 많은 관심을 쏟고 있습니다. 예전에는 아파치, MySQL 등이 제공되었고, 최근에는 하둡을 시작으로 한 다양한 분산처리 솔루션들이 제공됨으로써 소프트웨어/서비스 전문 회사가 아니더라도 쉽게 (빅)데이터를 관리, 분석할 수 있는 여건이 마련되었습니다. 사회적 관심도 높아졌고 다양한 기반 솔루션들도 존재하지만, 국내에서는 여전히 데이터 기반의 그것 something이 부족하다는 것을 느낍니다.
다른 곳들보다 -- 특히 비IT 기반의 제조업체 등 -- 다음이라는 회사가 여러 면에서 데이터 기반의 실행이 가능한 곳이지만, 외부에서 짐작하는 것에 비하면 여건이나 프랙티스가 미약합니다. 별것도 아닌 추천 서비스들도 최근에 일부 적용되고 있고, 대부분의 서비스들은 여전히 수작업을 거치는 것이 현실입니다. 가볍게 실행해보고 효과를 파악한 후에 그만두거나 더 드라이브를 걸거나 하는 그런 실행조직으로써의 문화가 많이 부족하다고 생각합니다. 물론 아니면 말지 식의 사고는 위험합니다. 그러나 오늘날은/현실에서는 그것보다 더 효과적인 전략도 없는 듯합니다. (애플이 될 수 없다면, 실행에 더 방점을 찍어야 합니다.) 다음이 이렇다면 다른 회사들은 어떨까?라는 생각을 하게 됩니다.
추천 시스템의 역사가 20년이 넘었기 때문에 단순한 직관/휴리스틱만으로는 추천 알고리즘의 발전이 거의 없습니다. 그래서 데이터마이닝 또는 머신러닝 분야에서 개발된 다양한 알고리즘들이 추천 시스템에도 접목되고 있습니다. 소개해드린 넷플릭스 논문에서도 소개되었지만, 웬만한 알고리즘들이 추천이라는 우산 아래 모여있는 것을 볼 수 있고, 또 여러 알고리즘들이 결합되어 새로운 알고리즘을 만들어내고 있습니다. 넷플릭스 프라이즈에서도 새로운 알고리즘의 승리라기 보다는 기존 아이디어들의 재발견 (또는 아상블 emsemble의 승리)에 가까웠습니다. 초기에는 추천이라는 문제를 바탕으로 다양한 방법론/휴리스틱들이 개발되었지만, 최근에는 다양한 연구 커뮤니티의 기술들이 추천이라는 문제를 풀기 위해서 이합집산하는 느낌이 강합니다.
추천 알고리즘에서 미처 설명하지 않고 넘어갔던 것이 하나 있습니다. 흔히 '장바구니 분석'이라는 기술이 있습니다. 책이나 블로그 등에서 자주 언급되는 아기 아빠들이 기저귀를 사면서 맥주를 함께 사더라라는 역사적인 연구에 등장하는 것이 장바구니 분석입니다. 함께 구매한 상품을 찾아내는 장바구니 분석은 CF의 아주 협소한 영역입니다. CF에서 한 사람의 이력 기간을 세션 (장바구니) 단위로 끊어서 분석하면 장바구니 분석과 비슷한 효과가 나옵니다. 그런데 CF는 아이템 페어 Pair-wise로 추천이 이뤄지지만, 장바구니 분석은 여러 아이템들이 함께 묶이는 형태로 결과가 나옵니다. 기술적으로 더 궁금하신 분은 Association Rule 또는 Frequent Pattern Mining으로 검색해보시면 됩니다.
PR시리즈 첫 글에서 제가 어떻게 해서 추천 시스템을 시작했는지 정확한 기억이 없다고 말씀드렸습니다. 지금 생각해보면 추천 시스템을 공부하기 직전까지 문서와 키워드의 관계 Vector Space Model (VSM)를 이용한 텍스트 마이닝을 연구/고민하고 있었고, 스트링커널 String Kernel을 이용해서 다양한 형태의 XML Schema 문서들 간의 유사도를 구하는 연구를 진행했습니다. 텍스트마이닝에 사용한 VSM이 추천 알고리즘에서의 유저-아이템 레이팅 행열과 똑같은 형태를 이루고 있습니다. VSM은 보통 TF-IDF로 문서와 키워드 관계를 설명하고, 이를 바탕으로 LSA/I (Latent Semantic Analysis/Indexing) 또는 PLSI (Probabilistic LSI)로 클러스터링 등을 수행하는데, 여기에 사용되는 LSA/LSI가 MF방식의 SVD와 같은 개념이 적용됩니다. 문서, 키워드, 유저의 관계/그루핑을 연구하던 것을 자연스레 유저-아이템 관계를 분석/예측하는 것으로 전환시켰던 것같습니다.
(계속...?)
추천시스템 전체 목록
- 추천 시스템과의 조우 (PR시리즈.1)
- 추천 시스템을 위한 데이터 준비 (PR시리즈.2)
- 추천대상에 따른 추천 시스템의 분류 (PR시리즈.3)
- 알고리즘에 따른 추천 시스템의 분류 (PR시리즈.4)
- 추천 시스템을 위한 유사도 측정 방법 (PR시리즈.5)
- 추천 시스템의 성능 평가방법 및 고려사항 (PR시리즈.6)
- 추천 시스템에서의 랭킹과 필터링 문제 (PR시리즈.7)
- 추천 시스템의 쇼핑하우 적용예 (PR시리즈.8)
- 개인화 추천 시스템에 대하여 (PR시리즈.9)
- 추천 시스템의 부작용 - 필터버블 (PR시리즈.10)
- 추천 시스템의 레퍼런스 (PR시리즈.11)
- 추천 시스템에 대한 잡다한 생각들 (PR시리즈.12)
- 추천 시스템을 위한 하둡 마훗 사용하기 (PR시리즈.13)
- 추천 시스템에 대해서 여전히 남은 이야기들 (PR시리즈.14)
==
페이스북 페이지: https://www.facebook.com/unexperienced