늘 그렇듯 어쩌다 AI 검색을 짧게 조사하게 됐다. 내가 관심 있는 부분은 과연 AI 검색은 시스템 구조상으로 기존 키워드 검색과 어떻게 다른지를 확인하고 싶었다. AI 검색에 관한 긴 설명과 장단점을 나열한 소개글은 많았지만 보고 싶었던 구조적 차이를 설명하는 그림과 글은 찾을 수 없었다. 없으면 직접 만드는/그리는 것이 공돌이의 숙명이기에 아는 범위 내에서 최대한 간략히 두 시스템을 비교하는 그림을 아래와 같이 그렸다. 한때 검색 분야에서 살짝 발을 담갔지만 AI 검색은 거의 문외한이기 때문에 아래의 그림과 설명이 실제와 다를 수 있음을 미리 밝힌다.
ChatGPT가 나온 후로 AI가 검색을 변혁시킨다는 주장을 별로 대수롭지 않게 생각했다. 그냥 기존에 검색을 장악한 구글이 잘할 거라 생각했다. Perplexity나 you.com 등이 AI 검색을 한다는 얘기를 계속 들었지만 그냥 찻잔 속의 태풍정도로 생각했다. MS가 OpenAI와 협력해서 AI 검색을 내놓더라도 의미 있는 트래픽을 얻지는 못하리라 생각했다. 이런 생각의 이유는 특정 질문 Query의 상위 검색 결과를 LLM에 Context로 넣고 적당히 Prompting 하면 그게 AI 검색이라 생각했다. 즉, 그냥 기존 키워드 검색에 생성형 AI를 Wrapping 하면 AI 검색이 될 거라는 막연한 생각이었다. 그런데 아래 그림처럼 Crawling을 제외하면 AI 검색은 기존의 키워드 검색과 완전히 다르다. 물론 아래와 다른 형태의 AI 검색도 가능하니 단정 짓지는 않겠다. 아래 그림을 그린 첫 번째 이유가 AI 검색이 키워드 검색과 구조적으로 많이 다르다는 점이었지만, 두 번째 이유는 의외로 AI 검색에 사용된 기술들은 이미 이전에 다른 경험에서 대부분 사용하던 거였다는 점이다.
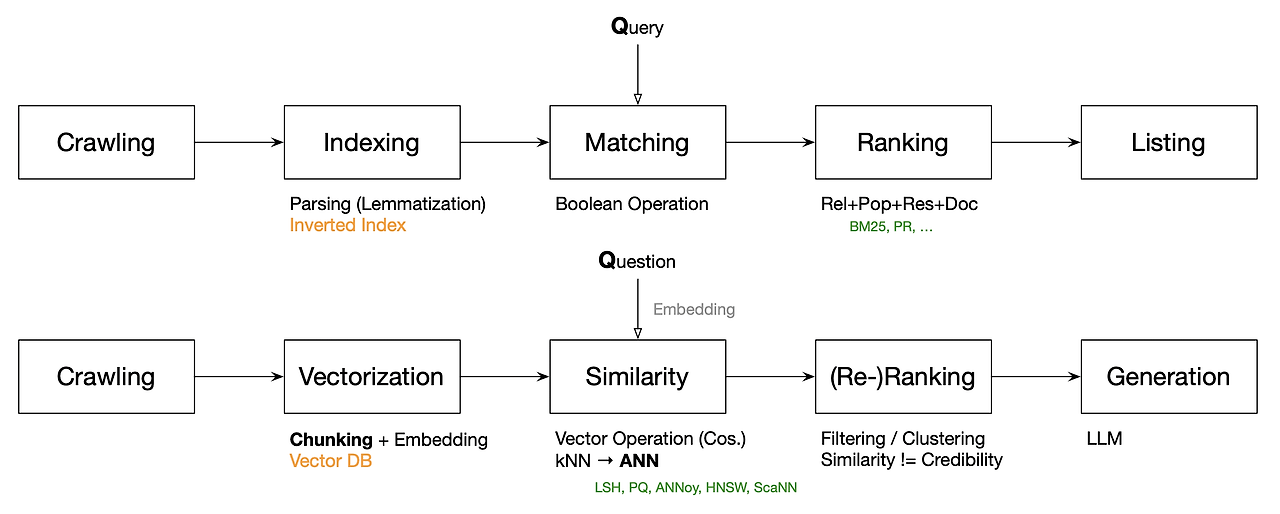
기존 키워드 검색은 1) 웹 문서를 수집 Crawling 한다, 2) 문서를 Parsing 해서 색인을 만든다, 3) 주어진 키워드 Query를 포함하는 문서를 찾는다, 4) 기준에 따라서 매칭된 문서를 정열 한다, 마지막으로 5) 순서대로 보여준다의 과정을 거친다. 반면 AI 검색은 크롤링을 제외한 다른 모든 과정이 이와 다르다. 수집된 문서들을 2) 적당히 쪼개어 임베딩 작업을 통해서 수치 벡터로 만든다, 3) 주어진 질문 Question의 임베딩 벡터와의 유사도가 높은 상위 문서 (또는 chunk)를 추린다, 4) (optional) 다른 기준으로 문서를 추린다, 마지막으로 5) LLM을 이용해서 검색 요약문을 생성한다 순으로 AI 검색이 실행된다. 단순하게 본다면 AI 검색은 큰 RAG (Retrieval Augmented Generation)이다.
세부 기술이나 알고리즘에 대한 자세한 설명은 생략한다. 키워드 검색은 쿼리를 색인 (역색인)에서 Boolean 연산으로 매칭된 문서를 찾아서 적당한 랭킹 알고리즘으로 나열하는 거다. 반면, AI 검색은 문서 (또는 chunk)를 수치 벡터로 만들어서 Vector DB에 저장하고 임베딩된 질문과의 유사도를 기반으로 질의결과를 찾고 생성하는 거다. 모든 검색에서 가장 중요한 과정은 Crawling이지만 (데이터 없는 분석이나 서비스는 없다), AI 검색의 승패는 1) Chunking, 2) Embedding Algorithm, 그리고 3) Similarity Metric에 따라 결정된다고 본다. 게 중에서도 Chunking이 가장 중요해 보인다. 임베딩 알고리즘은 적당히 큰 차원에 데이터를 일괄적으로 projection 시킨다면 성능에 큰 차이가 없다. 유사도도 Cosine 유사도가 가장 낫다고는 하지만 대세를 바꿀 만큼 성능이 월등하다고 말하긴 어렵다. 하지만 어떤 chunking 방법을 사용하느냐에 따라서 검색결과의 품질이 180도 바뀔 수도 있다. Chunking에 관한 자세한 설명은 생략하지만 대략 Semantic chunking 류로 수렴한다. 다음으로 크롤링된 문서량이 많고 청크 개수가 많다면 유사도 계산에 많은 시간과 비용이 들어간다. 그래서 kNN을 approximate 하는 ANN을 사용해서 검색 시간을 줄인다. 대표적인 ANN 알고리즘들은 그림 참조. 마지막으로 이미 유사도에 따라서 문서를 선별했기 때문에 reranking은 다소 불필요할 수도 있으나 유사도만으로 결과의 품질을 담보할 수 없기 때문에 일종의 필터링의 의미로 리랭킹이 필요하다. 때론 결과 문서들이 모두 같은 주제가 아닐 수도 있으니 클러스터링 등으로 주제를 분류할 수도 있다.
AI 검색이 검색의 미래처럼 말하지만 키워드 검색을 완벽히 대체하지는 않으리라 본다. 이 둘의 장단점이 명확하기 때문이다. 먼저 키워드 검색의 Exact 매칭은 단점이기도 하지만 명확한 답이 있는 경우에는 더 효과적이다. 그리고 연산이 빠르고 비용이 저렴하다. 현재 LLM 기반의 AI로는 절대 넘볼 수 없는 치명적인 장점이다. 반면 AI 검색은 벡터 유사도에 따라서 매칭이 매우 느슨하다. 그래서 모호한 질문, 때론 오탈자를 포함하더라도 괜찮은 결과를 제공한다. 긴 문서들을 요약해서 새로 생성하기 때문에 리스팅보다는 상대적으로 검색 결과가 깔끔하다는 장점도 있다. 그리고 CLIP과 같은 Contrastive Learning 기반의 임베딩 알고리즘을 사용하면 텍스트 문서 외의 다양한 modality, 즉 이미지나 음성, 동영상 등에도 바로 적용이 가능하고 언어의 제약도 덜하다. 키워드 검색도 어느 정도 가능하지만, 개인의 이전 context 정보를 prompt에 추가하는 것만으로도 개인화된 검색 결과를 제공한다는 장점이 있다. 그 외에도 여러 장단점이 있으니 직접 여러 서비스를 사용해 보거나 구현해 보면서 확인하기 바란다.
