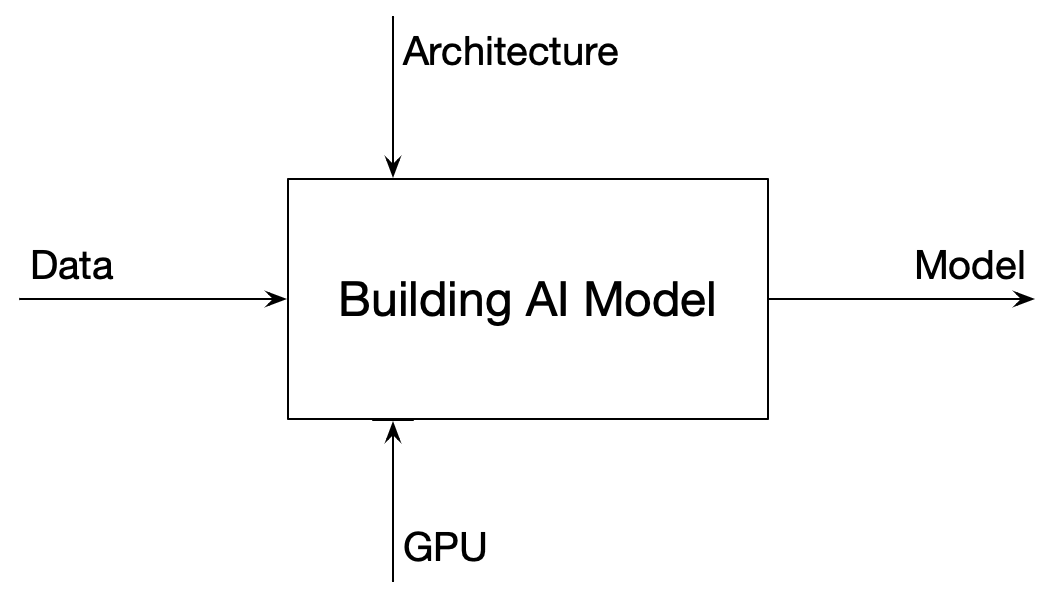
어떤 문제를 해결할 AI 모델을 만드는 것을 개념적으로 그리면 아래의 Functional Model과 같다. GPU로 대표되는 적당한 하드웨어를 갖고 있으면 문제에 맞는 모델 아키텍처와 알고리즘으로 관련 데이터로 모델을 학습하면 해당 문제에 특화된 AI 모델이 만들어진다. 문제 복잡도에 따라서 아키텍처 종류나 규격 또는 필요한 데이터 양이 다를 수 있으나 잘 훈련된 혼자 또는 소수의 데이터 과학자만 있으면 꽤 괜찮은 모델을 학습해서 운영할 수 있’었’다. 지난 1년을 되돌아보면 LLM과 Diffusion 모델로 대표되는 생성형 AI가 대중에게 소개되면서 AI 모델을 구축하는 양상이 바뀌었다. 고전이 여전히 필요하지만 거대함이 요즘의 핵심이 됐다. 개발의 양상이 바뀐 거다.
2023년에 만들어진 LLM의 종류와 개수가 이전까지 만들어진 모델보다 더 많다. 일반인들은 OpenAI ChatGPT (i.e., GPT), 구글 Bard (i.e., LaMDA, PALM, Gemini), 그리고 메타의 오픈 모델인 LLaMA 정도만 알겠지만, 지난 1년 동안 수십 종의 LLM들이 발표됐다. LLaMA에서 파생된 알파카나 비쿠나 등이 개발자들에게 친숙하지만 이들도 내 기억 속에선 까마득히 옛날 모델들이다. 세계 유수의 주요 테크기업들이나 IT 스타트업들이 웬만하면 자신들의 모델을 갖고 있다. OpenAI의 GPT 모델을 라이선스 받아서 사용하는 MS 조차도 Phi 모델을 꾸준히 업데이트하고 있고, 미중 패권의 다른 축인 중국 기업들도 정부 승인이 난 후로 여러 모델들을 공개하고 있다. 국내만 하더라도 네이버의 하이퍼클로버, LG의 액사온, KT의 믿음, 초반에 AskUp으로 더 알려졌던 UpStage의 Solar, 그리고 삼성의 가우스 (참고로, GAUSS 네이밍은 본인의 제안임^^ 네, 가우스전자(도) 맞습니다. 웹툰이 계속 연재했다면 가우스전자의 SAM 인공지능모델을 만드는 것도 상상했습니다.), 그 외에 일반에 덜 알려진 크고 작은 LLM 모델들이 존재한다. 대표적인 AI 강국인 미국과 중국 (그리고 대한민국)을 제외하고 가장 눈에 띄는 모델은 UAE의 Falcon과 프랑스 Mistral (& Mixtral) 등도 있다. 그 외에도 Arxiv의 AI 카테고리를 계속 모니터링하면 매달 크고 작은 모델들이 특정 태스크나 특정 언어에 특화해서 꾸준히 소개되고 있다.
지난 1년 동안 LLM 모델의 발전 양상을 짧게 요약하면, 1) 트랜스포머 모델을 조금 변형해서 더 긴 입력(context)에 대응, 2) Quantization을 비롯해서 더 가볍고 빠르고 저전력 모델의 개발, 3) 모델 사이즈 경쟁, 4) 양질의 데이터 (훈련 데이터와 벤치마킹 데이터) 확보, 5) 몰티모달, 멀티링규얼로 확대 등으로 정리된다. 온디바이스를 위한 모델 경량화도 큰 축이지만, 더 많은 양질의 데이터를 모아서 더 강력한,, 즉 더 거대한 모델을 개발해서 경쟁자를 압살 하는 것이 AI 회사들의 미션처럼 보이기도 한다. 이런 경쟁이 좋기도 하고 나쁘기도 하다. … 지금 '돈의 게임’이 벌어지고 있다는 최근 생각을 설파하기 위해서 길고 구차하게 적고 있다.
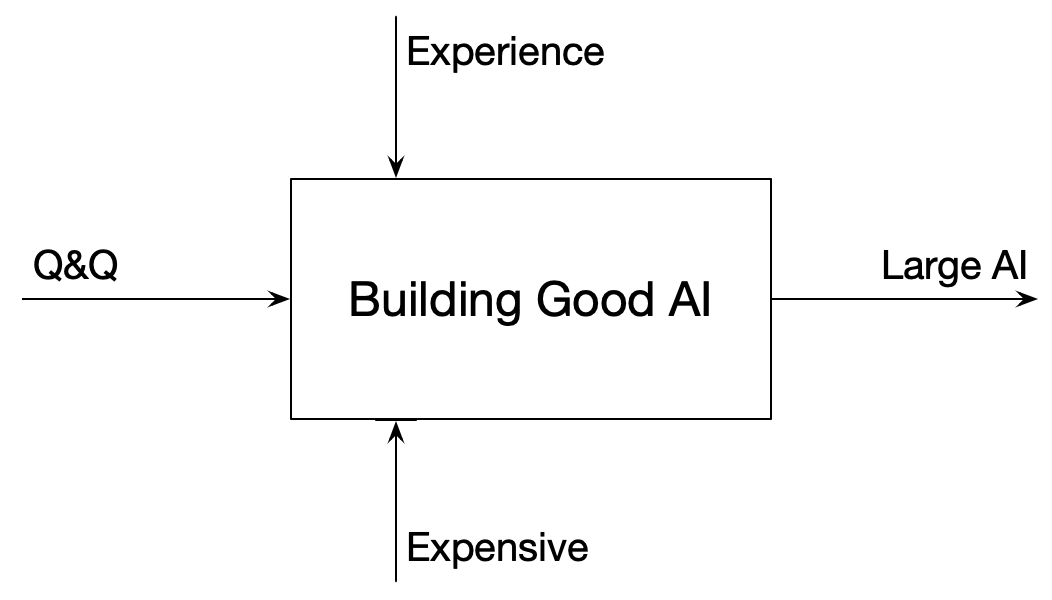
요즘의 거대 AI 모델을 구축하는 것도 기본적으로 위의 그림과 같지만, 양상은 조금 바뀌었다. 아래에 그림으로 그렸지만, 1) 양질이 데이터가 엄청나게 많아야 한다 (Quality & Quantity), 2) 기본 모델 아키텍처는 큰 변화가 없으나 잘하려면 경험/노하우가 많은 과학자/엔지니어가 많이 필요하다, 3) 게임용 GPU 장비 몇 대로 해결되지 않고 클라우드와 GPU 팜이 필요하다. 어차피 모델 (트랜스포머 아키텍처)는 공개됐기 때문에 누구든 마음만 먹으면 괜찮은 LLM 모델을 만들 수 있다. 그러나 아무나 만들 수 없게 됐다는 게 이 글의 요점이다. 아주 어마무시하게 많은 돈이 있는 사람 또는 집단만이 AI 설루션을 만들어서 제공하는 시대가 됐다는 자조다.
지난 11월에 OpenAI의 Sam Altman Saga로 한동안 시끄러웠다. 그때 내 눈에 가장 띈 것은 현재 OpenAI의 직원이 약 770명이고 이들이 GPT와 관련 서비스를 개발하고 있다는 거였다. 구글이 Gemini를 발표했을 때 Technical Report에 10 페이지가 넘도록 참여자들의 명단이 적혀있었다. Arxiv에 이 리포트를 공개했을 때 대략 940명의 이름이 요약 페이지에 적혀있었다 (https://arxiv.org/abs/2312.11805). 소수의 천재보다 다수의 협력이 필요한 것이 AI 개발이다. 1,000명 직원의 1년 연봉을 합치면 얼마가 될까? 여전히 돌파구를 마련하기 위해서 천재가 필요한데 그 천재의 몸값은 과연 얼마일까? 여전히 천재 개발자 Nerd를 동경하지만 AI 시대에 그런 자발적 개발자를 상상할 수 있을까? 돈이 있는 회사들만이 저 많은 개발자 또는 천재를 고용해서 AI 모델을 만들 수 있는 시대다. GPU 팜을 구성할 수 있는 것도 대기업이 아니면 거의 불가능하다. 대용량의 양질의 데이터를 확보하는 것도 경제력이 없으면 불가능하다. AI 기업과 콘텐츠 생성자 (책이나 뉴스 등) 간의 lawsuit이 흔해졌고, 거액의 라이선스 계약이 이뤄졌다는 뉴스가 끊임없이 나오고 있다. 다양한 실험 데이터가 풍부해졌지만 요즘의 AI를 구축하고 자신들만의 특성을 드러내기에는 여전히 데이터가 부족하다. 데이터 확보는 지갑의 깊이에 달렸다. 매우 많고 다양한 LLM 모델들이 만들어지는 것을 보면 LLM 자체를 구축하는 것이 별로 어려운 일이 아님을 알 수 있다. 그런데 Falcon 모델이 어느 나라의 지원을 받아서 만들어졌는지를 생각해 보면…
그럼에도, 여전히 난세의 영웅, 천재의 숨결을 기다린다.

