달고나 19에서 불확실성이 과금 방식의 변화를 이끌었다고 설명했다. 광고주의 불확실성을 해소하기 위해서 전환 중심의 광고가 나올 수밖에 없지만, 플랫폼은 오히려 확실한 트래픽에서 불확실한 전환으로 전이됨으로써 큰 공경에 빠질 수 있다. 만약 플랫폼이 전환을 정확하게 예측할 수 있다면 광고주의 불확실성과 플랫폼의 불확실성을 모두 해소할 수 있다. 하지만 정확한 전환 예측이 어렵기 때문에 문제다. (노출 후) 클릭 (CTR)은 거의 정확히 예측하고 있으니 개념적으로 보면 (클릭 후) 전환 (CVR)도 쉽게 예측할 수 있으리라 오인할 수 있다. 이 글에선 왜 전환 예측이 어려운지 대략적으로 설명한다.
2018년도 If Kakao에서 발표한 슬라이드를 가져왔다. (참고로 상단의 Imp/Click/Conv 그림은 빈도, 시차, 다양성을 도식화한 거다. 그리고 2018년에도 같은 슬라이드로 글을 적었는데, 브런치에 새로 적은 걸 가져옴)
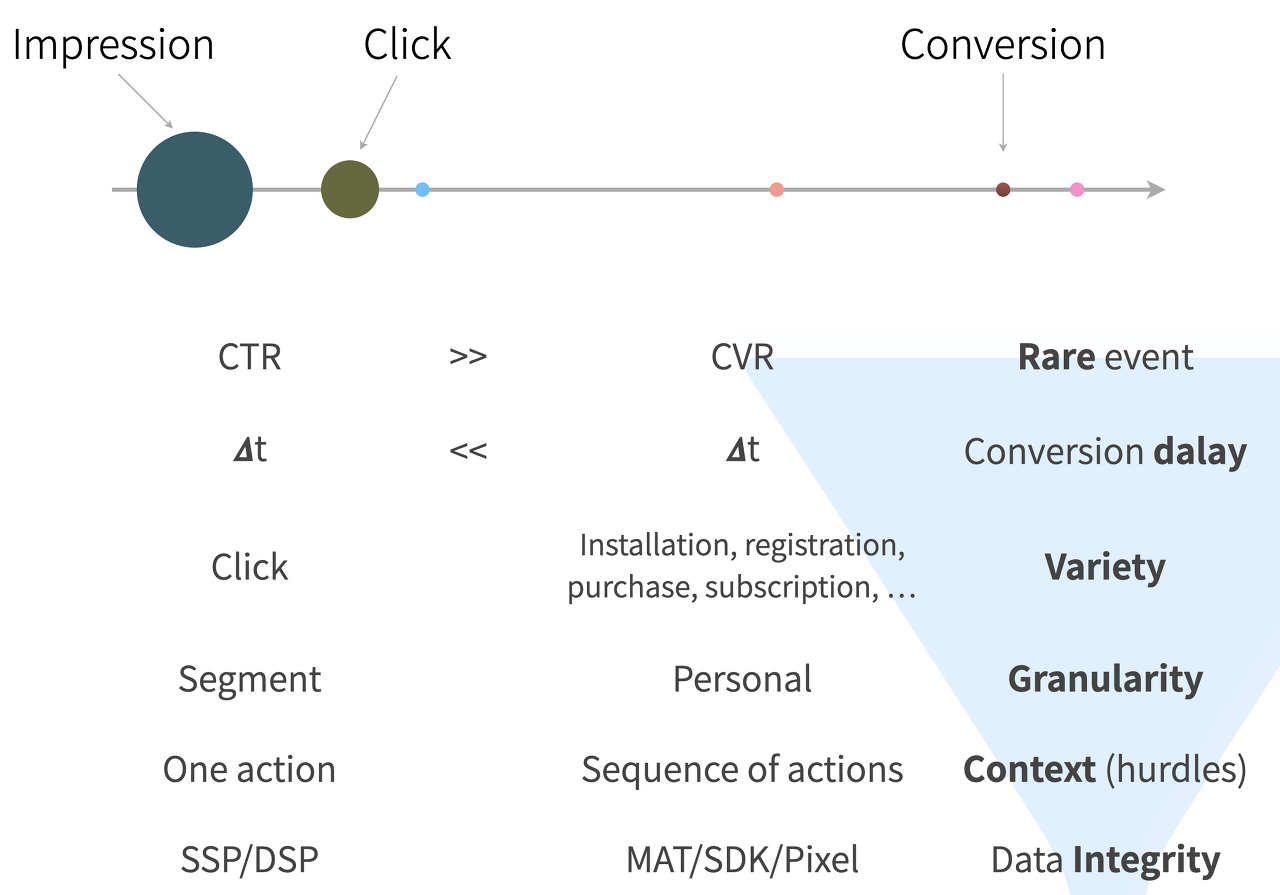
첫 번째 이유는 사건 발생 빈도에 있다. 사건의 발생 빈도가 잦거나 주기적이면 예측이 다소 쉽고 꽤 정확하다. 열 번 중에 한 번 발생하는 사건과 백 번 중에 한 번 발생하는 사건을 예측하는 것과 비슷하다. 광고가 노출되는 지면 (Inventory)의 위치나 크기, 또는 노출되는 광고 소재의 종류 등에 따라서 제각각이지만, 보통 디스플레이 광고의 CTR은 1% 정도로 보면 된다. 즉, 광고가 100번 노출되면 1번 클릭이 발생한다. 아주 효율이 좋은 지면 & 소재면 극히 예외적으로 10%까지도 나오기도 하지만, 보통은 1~2% 또는 그 이하라 보면 된다. 그런데 전환율은 클릭률의 10 분의 1 (또는 100 분의 1)이다. 노출 1,000 (또는 10,000) 번에 전환 한 건이 발생한다는 얘기가 아니라, 클릭 1,000 (또는 10,000) 번에 전환 1건이 발생한다는 얘기다. 즉, 10만에서 100만 번 광고가 노출되면 실제 전환이 1회 정도 발생한다고 보면 된다. (워낙 케이스가 다양해서 이보다 훨씬 효율 좋은 광고도 있고, 못한 경우도 있다.) 단순히 수치가 적어서 예측하기 어려운 면도 있지만, 충분한 학습 데이터를 구하기 어렵기 때문에 예측하기 어렵다. 만약 eCPM이 3,000이면 1 노출 단가는 3원이 된다. 예산이 100만 원이라면 33만 회의 노출을 확보할 수 있고, 1%의 CTR을 가정하면 3,300회의 클릭 데이터 (y = 1)를 얻을 수 있다. 같은 상황에서 산술적으로 1건의 전환 데이터도 얻을 수 없거나 많아도 (CVR=0.1%인 경우) 겨우 3~4건의 전환 데이터를 얻을 수 있다. 안정적으로 예측 모델을 학습하기 위해서 최소 수백 건의 라벨링 데이터 (y=1)가 필요한데, 낮은 전환율 상황에선 충분한 학습 데이터를 얻을 수 없다. 라벨링 데이터가 적으면 노이즈에 취약하거나 일부 데이터 과하게 편향될 수도 있다. 학습 데이터의 질이 떨어지면 학습된 모델의 정확도가 떨어지는 것은 당연하다. (참고. CTR = #clicks / #impressions, cvr = #conversions / #clicks)
두 번째 이유는 사건의 발생 시점에 있다. 광고를 노출한 후에 거의 99% 클릭이 1분 내에 발생한다. 즉, 일부 미매핑 데이터는 그냥 버려버리고 실시간으로 라벨링된 학습 데이터 (X-Y)를 만들 수 있다는 얘기다. 반면 클릭 후 전환까지의 시간은 종잡을 수 없다. 전환의 종류에 따라서 다소 차이가 있지만, 하루 뒤에 전환이 발생하기도 하고, 일주일 뒤에 발생하기도 하고, 때론 한 달 뒤에 발생하기도 한다. 전체 전환의 50% 이상은 한 시간 내에, 7~80%는 하루 내에 발생한다는 점이 그나마 다행인 점이다 (대략 어림잡은 수치임). 사용자의 롱텀 또는 글로벌한 랜드스케이프를 모르기 때문에 가능하면 실시간으로 반응 데이터를 수집해서 예측모델을 빨리 업데이트함으로써 실시간 트렌드를 쫓아가면서 예측하는 것이 정확도를 유지하는 좋은 전략인데, 지연된 전환 데이터는 이 전략을 효과적으로 사용하기 어렵게 한다. 전환 학습 데이터 (X-Y)를 실시간으로 수집할 수 없어서 가뜩이나 모델의 정확도가 낮은데 더 낮아질 수도 있다. 어떤 노출/클릭 (X)에 대해서 한 시간 내에 전환이 발생하지 않아서 y = 0으로 학습했는데, 3일 뒤에 전환이 발생해서 다시 y = 1로 바꾸는 상황이 발생하는 걸 상상해 보자. 그러면 해당 X에 대한 y는 0이면서 1이 되는 셈이다 (다소 쉬뢰딩거의 고양이처럼 양자학적이다). 이런 상황 때문에 Delayed Feedback을 가정한 예측 모델에 관한 여러 연구들이 있다. 그런데 이런 DFM은 단순 Logistic Regression보다 예측 정확도가 낮을 뿐만 아니라, non-convex 문제여서 최적화도 쉽지 않다.
세 번째는 전환의 종류가 다양하다는 점이다. (참고. 클릭도 전환 (또는 action)의 한 종류이긴 함) 노출과 클릭은 잘 정의돼있지만, 전환은 그렇지 않다. 전환 예측 모델 A는 '구매' 전환을 잘 예측하지만 '회원 가입'이나 '앱 인스톨' 등의 다른 전환은 잘 예측할 수 없다. 물론 같은 알고리즘/방법론을 사용하겠지만, 전환의 종류가 바뀌면 예측 모델도 함께 달라야 한다. 전환의 종류에 따라서 수집되는 전환의 수도 다르고 전환이 발생하는 시점과 분포가 모두 다르다. 전환의 종류 간에 지식의 transfer도 다소 가능하지만, 기본적으로 전환의 종류별로 별도의 예측 모델을 학습해야 한다.
네 번째는 클릭은 사용자를 속성 sement 별로 묶을 수 있지만, 전환은 거의 개인 레벨에서 발생한다. 앞서 언급한 발생 빈도 (희소성)과 결합돼서 특정 개인이 전환할 것인가 말 것인가를 예측하는 것은 매우 어렵다. 클릭률은 사용자의 성별, 나이, 기본 관심사 등의 몇 가지 피쳐로 대략 예측할 수 있다 (또는 대강 퉁 칠 수 있다.). 전환을 예측하기 위해서는 이보다 더 다양하고 상세한 정보가 필요하다. 때론 모든 속성 (피쳐) 정보가 같더라도 완전히 다르게 행동한다.
클릭은 하나의 단일 액션으로 정의되지만, 보통 전환은 액션의 연속이다. 예를 들어, 광고를 통해서 어떤 쇼핑몰의 물건을 구입하는 걸 상상해 보자. 광고에 나온 '카메라'가 마음에 들어서 바로 구매하고 싶어도, '쇼핑몰 접속 -> 회원가입 또는 로그인 -> 상품 탐색 -> 장바구니 담기 -> 결제/배송 정보 입력' 등의 연속된 액션 단계를 거쳐야 한다. 이런 각각의 단계들이 전환의 방해물이다. 전환을 정확히 예측하더라도 중간 허들에서 전환에 실패할 수도 있다. 아니면 이런 허들을 모두 고려해서 전환할 것인지 여부를 예측해야 한다. 퍼넬처럼 각 단계별로 별도로 예측해야 할 수도 있다. 아니면 애초에 이런 허들이 적은 사용자 (예, 이미 회원 가입된 사용자)만을 대상으로 전환을 예측하고 관련 광고를 노출해야 할 수도 있다.
마지막으로 데이터 정합성/무결성 Integrity도 전환 모델의 정확도에 영향을 준다. 광고의 노출과 클릭은 광고 플랫폼이 관리하기 때문에 관련 데이터를 바로 수집할 수 있다. I 지면에 U 사용자에게 A 광고를 노출했는지 여부를 플랫폼이 바로 기록하고, 만약 U가 그 광고를 클릭하면 바로 클릭 데이터를 수집할 수 있다. 하지만 전환은 플랫폼의 관리 범위를 벗어난 곳에서 발생한다. 즉, 광고주 사이트 (예, 쇼핑몰)에서 구매 전환이 발생한다. 그 사이트에는 특별한 장치가 없으면 플랫폼에서 데이터를 수집할 수 없다. 그래서 외부 사이트에서 발생하는 다양한 이벤트를 수집하기 위해서 전환 트래커 (SDK/전환Pixel/MAT)를 설치해야 한다. 일단 소형 광고주들이 이런 전환 트래커를 설치하는 것부터 어렵다. 전환 트래커를 설치했더라도 이를 통해서 수집되는 데이터가 정확한지를 검증하거나 광고주 (또는 제삼자)를 신뢰하는 수밖에 없다. 극단적으로 광고주가 CPA 광고를 집행하는데, 광고비를 모두 주기 싫어서 50%의 확률로 트래커가 설치되지 않은 페이지로 트래픽을 유도해서 전환이 일어나지 않은 것처럼 속이는 경우도 상상할 수도 있다. 흔하지는 않겠지만 가짜 전환을 트리거할 수도 있다. 데이터 관리/수집의 주체가 다르면 데이터의 정합성부터 확보해야 한다.
요약하면 전환의 다양성과 희소성으로 전환을 정확히 예측하기 어렵다. 예측이 정확하지 않다면 그걸 기반으로 한 상품의 불확실성은 커질 수밖에 없다. 그래서 현실적으로는 예측한 수치를 그대로 사용하기보다는 일종의 참고용으로는 활용할 수 있다. 예측한 수치가 완벽하게 정확하지는 않더라도 최소한의 경향성은 파악할 수 있다. 어떤 광고에 대한 A의 전환 가능성은 10.345%이고, B의 전환 가능서은 8.285%다 식으로 엄격하게 예측하지는 못하더라도 최소한 A가 B보다 전환 가능성이 더 높기 때문에 A에게 우선 그 광고를 (더) 보여준다와 같은 좀 approximate 한 방식은 여전히 취할 수 있다.

