인공지능 (AI)의 가장 큰 문제점은 무엇일까? 이전까지는 모르겠으나, ChatGPT 이후로는 Hallucination (또는 Confabulation)이라고 가장 많이 답변할 거라고 추측한다. 특히 검색과 연계하면서 거짓말하는 AI는 상상하기 어렵다. 검색이 아니더라도 내 편하고자 이용하는 AI인데 내가 원하는 답변과 전혀 다른 엉뚱한 결과만 내놓는다면 실망할 게 뻔하다. 하지만 AI를 어떤 용도로 사용하느냐에 따라서 Hallucination이 별로 문제가 되지 않기도 한다. 초소 LLM에 한정해서 개인적으로 내린 결론은 AI는 확인 (Confirmation)과 확장 (Expansion)에 사용하고, 그 외의 분야에 적용할 때는 주의를 기울여야 한다고 본다. 확인은 내가 이미 알고 있는 것에 관한 것이고 확장은 내가 모르는 (상상할 수 없는) 것에 관한 것이다. 확인은 쉽게 검증이 가능해야 한다. 특정 한국어 문장을 영어로 번역한다면 둘 사이의 오류를 바로 확인할 수 있다. 긴 문장을 짧은 단락으로 요약한다면 시간이 다소 걸리더라도 제대로 된 요약인지 검증이 가능하다. 이렇게 바로 또는 쉽게 검증이 가능한 상황에서 내 수고와 시간을 단축하기 위해서 인공지능, 특히 LLM을 활용해야 한다. 반대로 상상력을 확장하는 영역에서는 오히려 LLM이 갖는 Hallucination-ability를 적극 활용하면 내가 미처 생각하지 못한 분야로 생각을 확장할 수 있다. 이렇게 확장된 것은 그대로 믿을 것이 아니라 내 지식의 영역으로 끌어와서 내 인식 영역을 확장한다. 몇 개월동안 고민하면서 내린 나만의 LLM의 효용성은 확인과 확장이다.
AI가 거짓말을 (항상) 한다는 것을 이미 알고 있으면 이게 틀릴 수도 있겠구나라며 경계하거나 재검증함으로써 문제를 해결할 수 있다. 그런데 답변이 그럴듯하면 이게 참인지 거짓인지 아리송해진다. 이런 경우가 오히려 항상 거짓일 때보다 더 문제가 된다. 그럴듯함이 AI가 갖는 가장 치명적인 문제라고 개인적으로 생각한다. AI의 그럴듯함은 모든 데이터와 AI 알고리즘의 태생적 한계에서 온다. 우리 일상에서 이런 그럴듯함을 꾸준히 접한다. 방송신문에서 올해 20세 남성의 평균 신장은 17x로 10년 전에 비해서 몇 cm 증가/감소했다라거나 2022년 신생아 중에서 가장 많은 이름은 남아 XY, 여아 XX라는 식의 기사를 자주 접한다. 업무 보고할 때도 A가 평균적으로 B보다 얼마 더 크고, C를 선택한 사람이 가장 많/적습니다 류의 말을 종종 한다. (샘플) 평균값, 최빈값, 미디언 등은 어떤 무리를 대표하기에 가장 적합한 방식임을 부인하지 않는다. 그래서 인공지능 알고리즘도 우리의 이런 관행에 기초해서 만들어졌다는 거다. 인공지능은 수많은 설루션 중에서 가능성이 가장 높은, 보통은 평균에 가장 가까운 답을 내놓는다. 어쩔 수 없지만 이게 인공지능의 태생적이며 가장 큰 문제라고 개인적으로 생각한다. 다른 이들은 다르게 생각할 수 있다. 제목의 ‘가능성의 함정’이란 인공지능이 내놓은 가능성이 가장 높은 답이 진짜 정답이 아닐 수 있다는 의미다. 이런 가능성에 의해서 Hallucination도 발생한다. 왜냐하면 언어모델(LM)에서 그게 가장 가능성인 가장 높았기 때문이다.
이전 포스팅에서 자세히 적었듯이 현재 LLM의 작동 방식은 A - B - C 다음에 올 확률이 가장 높은 D를 답변하는 방식이다. 왜냐하면 LLM이 사용한 수많은 학습 데이터 (텍스트 문서)에서 ABCE, ABCF, ABCG 등보다 ABCD가 가장 많았기 때문이다. 현재 상황에서 ABCZ가 가장 적합한 답일지라도 AI는 자신이 학습할 때 가장 많이 봤던 ABCD를 답으로 제시하는 것이 당연하다. 특별한 가정이 없으면 회귀모델 regression은 가우시안 분포를 가정으로 현재 주어진 X들에 대한 예측 평균값 Y를 답변할 거고, 분류모델 classification도 그 무리에 속한 초빈 라벨을 답으로 내놓을 거다. 클러스터링 clustering도 당연히 평균적인 무게중심 centroid 또는 medoid에 따라서 클래스가 나뉜다. 평균이든 최빈이든 그런 경향성에 따른 무리에 관한 예측은 틀리지 않지만, 개인 — 특히 아웃라이어 outlier — 개인에 관한 예측에서 종종 틀리는 이유다. 틀리지 않도록 학습된 인공지능에게 탓할 수는 없는 노릇이다.
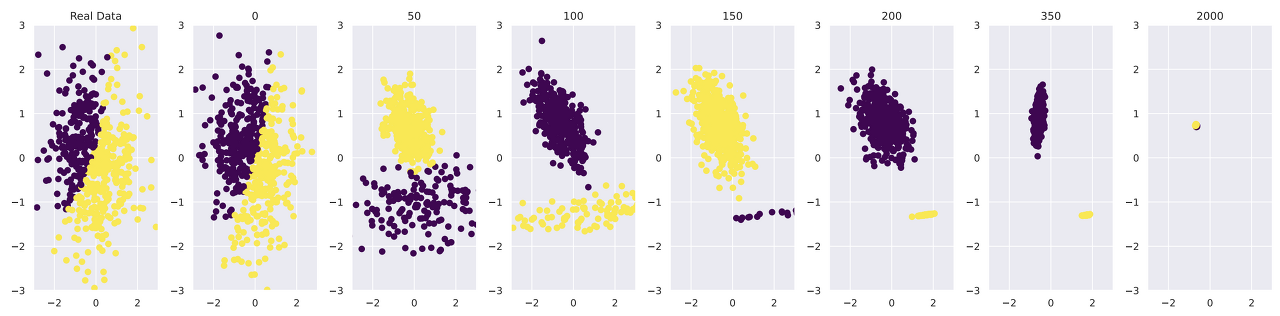
ChatGPT가 크게 관심을 끌기 시작하던 지난 2월 달에 New Yorker 잡지에 재미있는 기사가 올라왔다. 유명 칼럼니스트인 Ted Chiang이 적은 'ChatGPT Is a Blurry JPEG of the Web’ 제목의 글이다. 글을 모두 읽지 않았지만 글의 요지는 AI가 만든 저작물들이 많아질수록 AI 생태계가 무너질 수 있다는 거다. (점점 복사기란 기기에 관한 기억오 흐려질 듯) 복사기로 복사한 문서를 다시 복사기로 복사하는 것을 반복하다 보면 어느 순간부터 복사물의 내용을 확인할 수 없어지듯이 AI 저작물이 다시 AI 모델의 학습데이터로 사용되면 모델 성능이 떨어질 거라는 거다. 아주 미세한 오류도 반복해서 누적되면 치명적이 될 수 있다. 사고실험으로 충분하지만 이를 직접 확인한 연구결과가 있다. 개인적으로 — 이 글에서 ‘개인적으로’라는 표현을 평소에 비해서 너무 자주 사용하는 듯함 — 최근 몇 달간 나온 연구들 중에서 가장 치명적인 연구로 뽑을 수 있다. The Curse of Recursion: Training on Generated Data Makes Models Forget 이란 제목의 논문이다. 자세한 건 논문을 직접 읽어보기 바라고, 아래의 예시 캡처처럼 AI가 만든 결과물을 다시 학습데이터로 사용해서 새로운 AI 모델을 만드는 과정을 반복하면 처음에는 실제 데이터와 비슷한 분포를 갖는 결과물을 만들어내지만 세대를 거듭할수록 평균에 가까운 값만을 생성하고 더 극단적으로 세대를 늘렸을 때는 원본의 특성을 전혀 반영하지 않는 엉뚱한 결과물을 만들어낸다. 지금 한참 유행 중인 LLM이나 Stable Diffusion 등의 Generative (생성형) AI로 만들어진 텍스트, 이미지, 음악 등의 저작물들이 많아지고 이들이 다시 학습데이터로 재사용되면 단기간 내에 현재 AI 생태계가 무너질 거다. 기대를 모았던 AI detection 기술도 온전하지 못한 것으로 판명되고 있고, 그래서 처음부터 AI 저작물임을 밝히는 watermark 기술에 관한 연구가 최근 활발하다.
평균값으로 대변되는 가능성만을 따르는 AI가 문제라고 적었지만, 이를 활용하기 나름이다. 평균을 잘 잡아내는 음악생성 AI가 있다고 가정하자. 우리는 이 AI에게 기쁨에 관한 음악, 슬픔에 관한 음악, XXX에 관한 음악 등을 만들라고 prompt 하면 인간의 감각으로 확인할 수 없는 평균적인 인간의 감정을 음악으로 들을 수도 있을 거다. 물론 편향 bias가 없다는 가정 하에... 문제가 있든 없든 한계가 있든 없든 어떻게 활용하느냐에 따른다. 결국 원인도 해결도 아직은 인간에게 달렸다.