아직은 인간의 시간이다.
지금은 기계가 지배하는 시기인가? 딥러닝이 다른 모든 알고리즘들을 평정하기 시작한 지도 10년의 시간이 지났다. 더 많은 사람들이 관심을 갖고 자금이 몰리면서 하루가 다르게 발전하는 인공지능 기술을 눈으로 확인한다. 여전히 실생활과는 조금 동떨어진 측면이 없진 않지만 변화 속도는 놀랍다. 터미네이터의 ‘스카이넷’이 내일 등장해도 놀랍지 않다. 하지만 인공지능 기술이 더 발전할수록 아직은 인간의 한계를 벗어나지 못하고 있다. 성능적 한계가 아니라, 아직은 사람이 이해, 설명할 수 없으면 기술을 쉽게 받아들이지 않으려 한다는 거다. 더 복잡하게 진화할수록 사람들은 내부 메커니즘을 이해하고 싶은 욕구는 더 커질 거다. 적어도 나는 그렇다.
이 글을 읽는 이들이라면 XAI (Explainable AI)라는 용어가 별로 생소하지 않을 거다. 앞서 말한 알고리즘의 내부를 알고 싶은 마음이 모여서 XAI라는 분야가 함께 발전하고 있다. 미안하지만 Interpretability 또는 Explainability를 한 단어 한글로 깔끔하게 표현할 방법이 없다. ‘설명가능성' ‘이해가능성’ ‘해석가능성’… 뭐가 됐든 우리가 기계를 완벽히 신뢰하기 전까지는 계속 인공지능 기술에 따라다닐 거고 역으로 인공지능을 설명 가능해질 때 우리는 기계를 완벽히 신뢰하게 될 거다. 그래서 때론 trust라고 표현하기도 한다. 그런 신뢰는 모델의 형태가 어떻고, 어떤 데이터를 사용하는지를 알 때 얻을 수 있으므로 때론 transparency라고 부르기도 한다. 메커니즘은 결국 인과성이므로 causality라고 부르기도 하고, 때론 많은 데이터와 서비스가 사람과 관련되기 때문에 fairness나 privacy와도 연결된다. 이런 interpretability 또는 interpretable machine에 관심이 있는 분이라면 다음 링크를 참조하기 바란다. 개인적으론 100% 정확한 알고리즘이 가장 interpretable 하다고 생각한다.
소수의 명확한 데이터를 사용한 간단한 simple 알고리즘이면 보통 interpretable 하다. 대강 변수가 100개 이내로 사람이 눈으로 모두 확인할 수 있고, 선형회귀와 같이 간단한 수식으로 표현된다면 interpretability는 획득된다. 하지만 그런 선형 모델로는 넘처나는 데이터의 종류와 양을 모두 처리할 수 없다. 그래서 보통 interpretability를 말할 때는 복잡한 모델을 가정하고, 그것의 결과물을 어떻게 해석할 것인가?를 위한 model-agnostic 방법론을 뜻한다. 즉, 모델 자체는 이미 복잡해졌기 때문에 부분적인 인풋-아웃풋 간의 민감도를 확인하는 편이다. 더 자세한 설명은 위에 걸어둔 링크를 참조하기 바란다.
여러 방법론들 중에서 현재 끝판왕은 SHAP (SHapley Additive exPlanations)인데, 이를 처음 제안한 논문을 읽어도 개념은 대강 알겠는데 구체적으로 어떻게 동작하는지 그리고 구글링으로 얻은 SHAP 관련 차트들을 어떻게 해석해야 하는지에 관한 감을 잡기 때문에 이 지면을 빌려서 기본 개념과 주요 그래프 해석법을 소개하려 한다.
먼저 Shapley value부터 알아보자. 노벨 경제학상을 수상한 Lloyd Shapley가 협력 게임 (cooperative game theory)에서 개별 플레이어들의 기여도를 수치화한 값이다. 보통 게임 이론 game theory 하면 비협력 게임인 죄수의 딜레마 (Prisoner’s Dilemma)를 떠올리지만 Shapley value는 협력 게임에 사용된다. 조별 과제가 대표적인 협력 게임이다. 현실에서는 조장의 1인 게임으로 변하지만, 이상적으로 (서로 역할을 나눠) 협력한다고 가정하자. 4명이 한 조를 이뤄 과제를 수행하여 최종 82점을 받았다면, 이 82점을 받는데 A/B/C/D가 얼마만큼 기여했는지를 수치화한 게 Shapley value다. 예를 들어, 과제를 수행했다면 기본 50점을 받는다고 가정하자. A는 자료를 수집했고, B는 발표 자료를 만들었고, C는 발표를 했고, D는 최종 보고서를 작성했다고 하자. 적당한 자료를 수집해서 20점, 발표 슬라이드를 잘 만들어서 10점, 발표 중 질의응답을 제대로 대응하지 못해서 -3점, 그리고 최종 보고서의 품질이 좋아서 5점의 점수를 받았다고 하자. 기본 점수를 제외하고 A/B/C/D의 기여도는 20/10/-3/5가 된다.
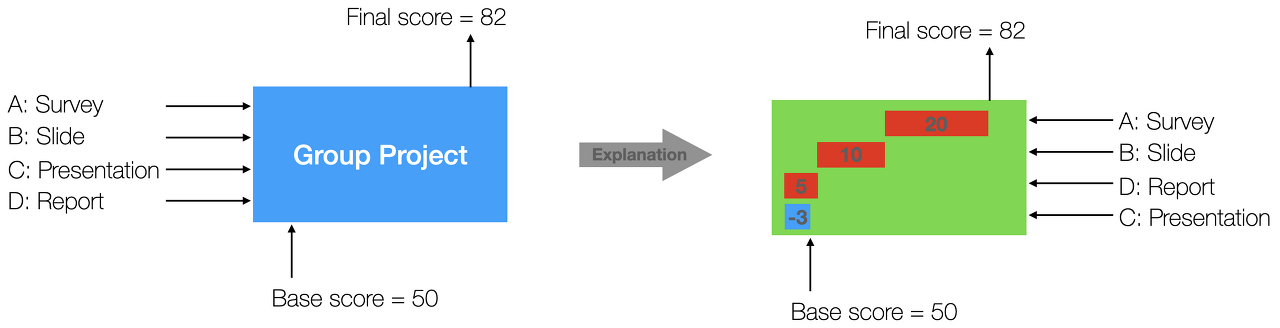
이런 Shapley value를 알고리즘에 적용하면, 어떤 변수의 존재 유무 (또는 값)에 따라 아웃풋 값의 변화를 측정한다. 단순히 변수 x의 값을 넣고 빼고 (1/0)에 따른 결괏값 y의 차이를 구하면 되는 것 아니냐?라고 생각할 수 있다. 그런데 변수들 간의 상호작용을 고려하면 이렇게 계산하면 특정 변수의 기여도를 완전히 파악할 수 없다. 그래서 모든 조합 coalition에서 변수 x의 유무를 고려한 값이 SHAP이다. 처음 제안한 논문을 여러 번 읽어도 구체적으로 어떻게 구하는지 이해할 수 없었는데, 다음의 towards data science (TDS) 글을 통해서 제대로 알게 됐다.
변수 x의 총개수가 n이라면 아래와 같이 2^n개의 모델을 만들어서 모든 변수의 유무에 따른 차이를 계산하는 것이 핵심이다. 가장 왼쪽 그림처럼 특정 변수가 있음/없음(1/0)으로 2개의 상태를 갖고, 총 n개의 변수이므로 모든 조합을 구하면 2^n이 된다. 모델 1은 X 없이 Y만으로 이뤄진, 즉 Y의 평균을 구하는 모델이다. 모델 2는 x1과 Y로 이뤄져서 Y = f(x1)이고, 모델 3은 Y = f(x2) 식으로 독립변수가 한 개인 모델들이다. 모델 n+2는 x1과 x2로 y를 예측하면 Y = f(x1, x2)가 되고, 같은 식으로 모든 변수를 사용한 모델 2^n는 Y = f(x1, x2, …, xn)이 된다. 이렇게 2^n개의 모델을 학습하고, 각 변수 별로 해당 변수가 존재하는 모델과 (다른 변수 조건은 동일하지만) 존재하지 않는 모델들을 찾는다. 예를 들어, 모델 1은 x1 없고 모델 2는 x1이 존재한다. 비슷한 방식으로 모델 2 (y = f(x2))와 모델 n+2(y = f(x1, x2))도 x1의 유무만 다르다. 이런 식으로 x1의 유무만 다른 모든 모델쌍들을 찾고, 각 쌍의 결괏값의 차이의 가중합 WS(x1)을 구한 것이 x1의 SHAP이다. x2 ~ xn도 같은 방식으로 계산한다. 모든 변수들의 조합에서 특정 변수의 유무에 따른 차이를 구하기 때문에 모든 변수들의 조합되는 상호작용도 고려한 특정 변수의 기여도를 얻을 수 있다. 하지만, 2^n개의 모델을 만들어야 하기 때문에 계산량이 많다는 단점이 있다. 이를 해결한 방식은 논문과 블로그를 참조하기 바란다.
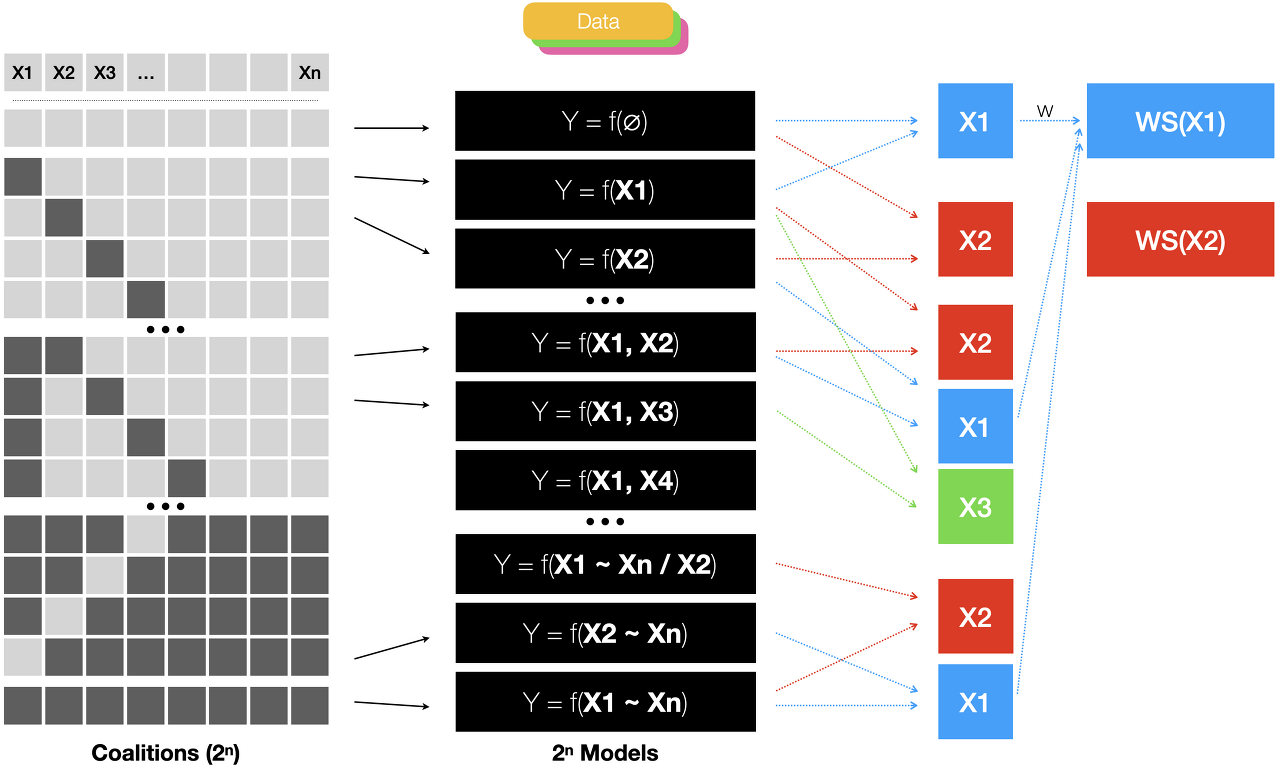
더 자세한 설명은 SHAP와 GitHub를 참조하기 바란다.
SHAP가 이 분야의 끝판왕이지만 변수들 간의 colinearity가 존재할 때는 값이 부정확하다는 단점이 있어서 수정한 버전이 ACV (Active Coalition of Variables)다. 자세한 설명은 링크를 참조하고, 간단히 설명하자면 먼저 변수들의 유의미 여부에 따라서 Active와 Null로 구분하고, active 변수들만을 이용해서 SHAP를 구한다.
다음으로 SHAP으로 검색했을 때 자주 등장하는 차트를 해석하는 법에 대해서 간단히 적는다. '모델을 해석하는 모델을 해석하는 방법'을 알려준다는 게 다소 아이러니다. 아래 차트는 TDS에서 가져왔다. N자 방향으로 1/2/3/4라고 하면, 1과 2는 개별 sample에 대한 SHAP을 그린 것이고, 3은 모든 샘플에서 절댓값 평균을 그린 것이고, 4는 모든 샘플을 모두 표현한 것이다.
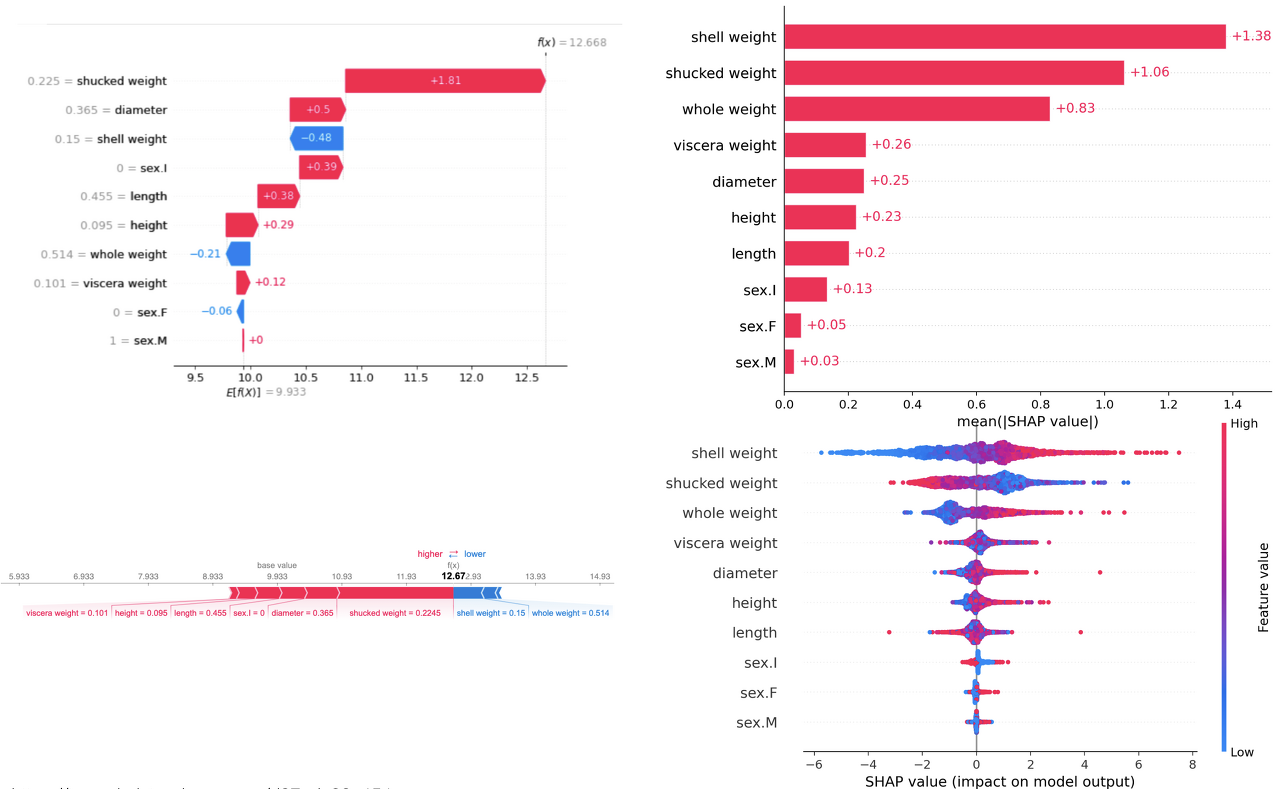
1과 2는 기본적으로 같은 그림이다. 우선 빨강은 positive 기여를, 파랑은 negative 기여를 뜻한다. 그림에서 E(f(X)) = 9.933 또는 base value (9.933)은 아무런 변수가 없을 때 y값이다. 조별 과제 예시에서 기본 점수 50점을 뜻한다. 여기에 빨강 변수들이 존재함으로써 + 쪽으로 y값이 증가하고, 역으로 파랑 변수들 때문에 - 쪽으로 감소한다. 1번 그림은 음양에 무관하게 기여도가 가장 큰 (폭이 가장 넓은) 변수부터 아래로 나열한 거고, 2번 그림은 음과 양을 그룹으로 모으고 최종 값 (12.67)을 기준으로 기여가 높은 것부터 밖으로 분산시켜놓은 차트다. Base value (9.933)에서 시작해서 빨강 변수들 때문에 13.xx로 증가하는데, 파랑 변수들 때문에 다시 약 0.75 감소해서 최종 12.67이 되는 셈이다.
개별 샘플들의 분석도 필요하지만, 어떤 변수가 전반적으로 얼마만큼 기여했는지를 보기 위해서 3번처럼 개별 샘플의 SHAP값의 절댓값을 평균해서 기여도가 높은 것부터 내림차순으로 그렸다. 1/2에서 shucked weight가 가장 컸는데, 3에선 shell weight가 평균적으로 가장 많이 기여해서 가장 우선 나온다. 절댓값을 취했기 때문에 방향을 얻을 수 없다. 마지막으로 4번 그래프는 모든 샘플의 SHAP 값을 그린 거다. 처음 이 그래프를 봤을 때는 어떻게 해석해야 하는지 긴가민가했지만 자세히 보면 의미를 쉽게 알 수 있다. 우선 오른쪽의 feature value 값은 각 변수의 값의 범위를 색으로 표현한 거다. 쉽게 이해하기 위해서 빨강은 1, 파랑은 0이라고 생각하면 된다. shell weight에서 빨간 점은 0을 기준으로 오른쪽 (+)에 다수 존재하고, 파란 점은 왼쪽 (-)에 존재하는 걸 볼 수 있다. 즉, shell weight = 1일 때는 양(+)의 기여를, 0일 때는 음(-)의 기여를 한 것이다. (shell weight는 범주형 실수 값이지만, 설명의 편의를 위해서 1/0으로 가정함) 그래프에서 뚱뚱한 부분은 샘플들이 그곳에 많이 위치했다는 의미다. shell weight는 값이 클 때, 역으로 shucked weight는 값이 적을 때 양의 기여를 한다는 걸 보여준다.
다른 종류의 그래프들도 제공하는데, 비슷한 방식으로 주의 깊게 살펴보면 해석하는데 별 문제가 없을 거다.
참고 링크
- https://christophm.github.io/interpretable-ml-book/
- https://shap.readthedocs.io/en/latest/index.html
- https://github.com/slundberg/shap
- (SHAP Explained) https://medium.com/towards-data-science/shap-explained-the-way-i-wish-someone-explained-it-to-me-ab81cc69ef30
- ACV https://github.com/salimamoukou/acv00


