지난주 금요일에 제주에서 대한인간공학회 춘계학술대회가 있었습니다. 프로그램을 준비하시는 분께서 '전문가 세션 > 빅데이터'에 발표해줄 연사가 필요하다고 해서 흔쾌히(?) 수락했습니다. 처음에는 단순히 다음이나 카카오에서 했던 다양한 분석 사례정도만 모아서 '카카오에서의 빅데이터 분석 및 활용' 정도로 발표하면 쉽게 될 거라 생각했습니다. 그런데 청자들이 데이터 분석을 담당하거나 적어도 프로그래머/개발자라면 쉬울 수 있는데, 대부분 인간공학 전공자들이라서 단순히 사례들만 모아서 장광설을 펼치면 죽도 밥도 안 될 것 같다는 두려움이 생겼습니다. 발표자료를 준비할 시간이 겨우 한달정도밖에 없었는데, 여러 고민을 하다가 인간공학을 전공하는 학생들에게도 도움이 될 수 있는 테스팅 방법론을 중심으로 준비하기로 마음을 정했습니다. 온라인 A/B 테스트에서부터 MAB (Multi-Armed Bandit)까지 다루면 될 것 같았습니다. 그런데 또 막상 자료를 준비하다보니 원래 취지가 '빅데이터'인데, 너무 지협적인 문제만을 다루는 듯해서 조금 일반화시켜서 '데이터 과학자의 삶: 신화와 실체'라는 제목으로 정했습니다. 발표자료에서는 '온라인 테스팅'을 중심으로 다뤘지만, 데이터 과학에서 가장 감추고 싶은 실체는 데이터 준비와 정제인데, 이 내용은 말미에 짧게 넣었습니다.

중요한 파트라서 화면을 캡쳐했는데... 실제 데이터 과학자들은 'SQL과 Data' 사이의 왔다갔다함이 일의 대부분이다. 여기서 인사이트를 얻으면 구현해서 테스트하고 배포한다. 아주 가끔 회귀분석이나 클래시피케이션 같은 고급 알고리즘을 사용하기도 한다. (KR = Knowledge Representation)
'김제동의 톡투유' 장면을 캡쳐했는데, 일반인들이 '빅데이터'에 대해서 생각하는 게 이런 화면이다. 많은 다양한 데이터를 모아서 빨리 가공해서 단어의 출현 빈도나 트렌드, 또는 키워드맵을 만드는 정도... 그러나 데이터에서 가치를 찾아내는 것이 요즘은 더 중요하다. 그래서 빅데이터보다는 스마트데이터로 변하고 있다. 단순히 엔지니어링 문제를 과학으로 바꾸는 것은 결국 분석력이다.
데이터 과학이 과학인 이유는 '과학적 방법'을 사용하기 때문이다. 과학적 방법은 1. 이론으로 증명하든지 2. 실험으로 검증하든지... 그런데 이론은 어렵다. 발표는 테스팅에 집중한다.
보통 과학에서의 실험은 문제에 대한 가설을 세우고 실험해서 실패하면 다시 가설을 세우고 다시 실험하고 이 과정을 반복하다가 실험이 성공하면 가설대로 논문을 작성해서 졸업하면 되지만, 서비스에서는 가설과 검증보다는 관찰과 테스트/비교를 거친다. 그리고 테스트가 성공해서 성공적으로 서비스를 런칭하더라도 다시 처음부터 관찰과 테스트를 무한반복한다. 그리고 온라인 테스트와 오프라인 테스트를 분리해서 진행하는 점도 특이하다. (넷플릭스는 일주일 단위로 '코드 배포 - 오프라인 테스트 - 온라인 테스트 - 서비스 배포'를 반복한다. 넷플릭스 개발자의 발표에서 직접 들은 것)
온라인 테스트는 A/B 테스트 또는 버킷 Bucket 테스트라고 한다. 파란 약과 빨간 약을 실제 사용자들에게 선택하라고 두고 많이 선택하는 걸로 정하면 된다. (인간공학회라서) 아이트래킹으로 비교할 수도 있다. 그런데 나는 데이터 과학자니 데이터로 확인한다. (같은 광고를 다른 타겟 사용자들에게 노출시키고 반응을 확인함)
A/B 테스트를 할 때 트래픽 기반으로 할 수도 있고 사용자 기반으로 할 수가 있다. (귀찮아서 그냥 글로 표현함)
50:50으로 실험군과 비교군을 만들 수 없다. 처음 런칭하는 서비스라면 괜찮지만, 이미 운영중인 서비스의 50%의 트래픽에 검증이 안/덜된 화면을 보여줄 수 없기 때문에 일부 (보통 5~10%)만을 실험군으로 정한다. 바이어스를 없애기 위해서 랜덤군도 둔다. 실험해야할 것들은 산적해있는데 매번 A/B로 나눠서 테스트하는 것은 여러모로 리소스 낭비이므로 실험군을 여러 개를 동시에 적용하고 모니터링 한다.
여담으로 네이버의 상징색이 녹색이듯이 다음의 상징색은 파란색이다. 처음에는 빨간색으로 하자는 의견도 있었지만 실제 사용자 반응에서 파란색으로 했을 때 PV나 클릭률 등이 더 높았다. (입사하기 전에 했던 전설로 들려오는 사례). 여담2. 외국의 경우 보통 엔지니어 중심으로 서비스가 만들어져서 데이터 기반으로 UI/UX를 정하는 것이 좀 일반적인데, 국내의 경우 처음부터 기획자나 디자이너가 함께 일하기 때문에 데이터 기반으로 화면을 구성하는 것이 오히려 더 낯선 풍경이다. (이미 기획자 및 디자이너들은 전문성이 있기 때문에 단순한 수치로 그들의 전문성에 의문을 제기하기는 어렵다. 그래서 UI/UX보다는 랭킹 관련된 곳에만 보통 온라인 A/B 테스트가 적용된다.)
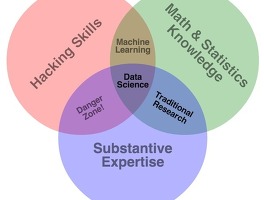
서두에 말했듯이... 데이터 과학자는 마치 꽃길만을 걸을 것 같지만 그렇지 않다. 그리고 데이터 과학에서 알고리즘보다는 데이터가 더 중요하다. 포브스의 기사에 이게 잘 나타나있다. 데이터 과학자들의 업부에서 20%는 데이터를 정의하고 수집하는데, 그리고 60%는 데이터를 정제하는데 사용한다. 그리고 이걸 가장 싫어한다. 그러나 이게 데이터 과학자들의 숙명이다. 이걸 얼마나 잘하느냐가 데이터 과학의 성패를 결정한다. 알고리즘은 중요하다. 그러나 데이터가 나쁘면 알고리즘은 그냥...
정리하면, 데이터 과학은 비즈니스 골을 획득하기 위해서 데이터를 해킹하는 것인데, '바른 데이터 > 바른 평가 > 바른 알고리즘'이다. 나는 데이터 과학자/해커지만, 여러분들은 이런 방법론이나 데이터를 사용해서 '인간 해커'가 되기를 바란다. 그리고 제주에서 즐거운 시간을...
=== Also in...