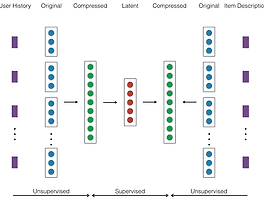
워드임베딩 (3) 썸네일형 리스트형 딥 개인화에서 해결해야할 문제들... 지난 글에서 워드임베딩에 대한 생각을 정리하고 딥러닝과 결합해서 개인화 추천에 어떻게 적용할 것인가에 대한 간단한 스케치를 올렸습니다. (참고. 워드임베딩: http://bahnsville.tistory.com/1139, 개인화 추천: http://bahnsville.tistory.com/1141) 오늘은 그런 기술을 딥 개인화 시스템에 적용할 때 예상되는 문제점들에 대해서 생각나는대로 정리하려 합니다. 지난 글에 제시한 딥 개인화 아키텍쳐를 간단히 설명하면 다음과 같습니다. 텍스트, 이미지, 또는 웹로그 등의 유저 및 아이템 정보/이력에 포함된 개별 항목들을 워드임베딩 기술로 벡터화한다. 유저/아이템의 정보를 RNN이나 CNN 등으로 정형화된 벡터로 압축한다.정형화된 유저벡터와 아이템벡터의 관계를 유저.. 딥 개인화 Deep Personalization 워드임베딩과 팩토라제이션을 설명한 지난 글에서 http://bahnsville.tistory.com/1139 저는 그 기술들을 크고 다양한 데이터 기반의 개인화 추천 data-rich personalization에 적용하는 것에 관심있다고 밝혔습니다. 이번에는 어떻게 개인화 추천에 활용할 수 있을 것인가?에 대해서 아이디어 차원의 글을 적습니다. 좀 naive할 수도 있음을 미리 밝힙니다. 불가능한 것은 아니지만 word2vec같은 워드임베딩 기술이나 SVD, NMF같은 팩토라이제이션 기술을 바로 개인화 추천에 이용하는 데는 한계가 있습니다. 유저별로 조회했던 아이템을 시간순으로 나열하고, 아이템을 word/vocabulary로 가정해서 아이템의 벡터를 만들 수 있습니다. 아이템 벡터의 cosine 유사.. 워드 임베딩과 팩토라이제이션, 그리고 개인화 Word Embedding, Factorization, and Personalization 여러 가지 개념이 혼재돼있습니다. 단어의 원래 뜻과 다르게 해석한 여지가 있습니다. 이 글에서 설명한 것이 절대적으로 맞다고 생각하면 위험합니다. 저는 제게 필요한 것으로 아전인수격으로 정의, 사용했을 개연성이 높음을 미리 경고합니다. 한글화된 용어를 별로 좋아하지 않지만 필요에 따라서 (국내에서 통상적으로 사용하는 경우) 일부 용어는 한글화했습니다. 2017년은 나름 공부하는 해로 정하고 그동안 미뤄놨던 논문들을 읽기 시작했습니다. 벌써 4주차가 됐는데도 여전히 논문을 읽고 있으니 지금의 흐름은 나름 오래 갈 것 같습니다. 한동안은 업무에 필요하거나 주목받은 논문 한두편을 짧게 읽은 적은 있지만, 연구실에 있을 .. 이전 1 다음