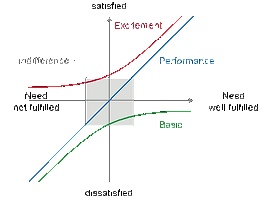
Kano model (1) 썸네일형 리스트형 서비스 기대와 만족 Expectation Minimization (Kano Model) 메타블로그나 검색엔진 등을 통해서 이 글이 머신런닝에서 말하는 EM (Expectation Minimization) 알고리즘에 대한 포스팅인 걸로 생각/기대하고 들어오신 분들에게는 먼저 죄송하다는 말을 전합니다. 이 글은 EM 알고리즘에 대한 것이 아닙니다. EM 알고리즘을 기대하셨던 분들에게는 제가 이 포스팅을 통해서 말하려던 바가 완전히 실패한 것입니다. 저는 여러분들이 가졌던 그런 기대와, 실제 제품/서비스들이 그런 기대를 충족시키느냐에 따른 고객만족 Satisfaction에 대한 글을 적으려고 합니다. (참고. 그렇지만, 제목에 사용한 Expectation Minimization은 분명 EM알고리즘에서 차용한 표현입니다.) 많은 서비스나 제품들을 출시하면서 기업들은 고객 만족의 정도를 측정하려고 .. 이전 1 다음